Generating Adversarial Prompts
Prompt Attack offers a sophisticated toolkit for generating adversarial prompts tailored to various scenarios. These prompts combine predefined categories with user-defined inputs, enabling comprehensive testing of Large Language Models (LLMs) for vulnerabilities. By simulating real-world threats, organizations can proactively identify weaknesses and strengthen their models' security and ethical safeguards.
Introduction
The process of generating adversarial prompts lies at the heart of Prompt Attack's capabilities. It allows users to create customized prompts by selecting specific attack techniques and vulnerability categories.
By using this approach, organizations can evaluate LLMs against a wide range of potential vulnerabilities, ranging from common attack vectors to more sophisticated and nuanced threats. This helps uncover critical weaknesses, guiding developers to implement necessary safeguards and ensure robust AI systems.
Safety Adversarial Prompts
Safety adversarial prompts assess whether an LLM can handle harmful or unethical requests without generating unsafe outputs. These prompts focus on mitigating vulnerabilities like:
- LLM09:2025 Misinformation: Testing whether the LLM spreads or rejects misleading information.
- Biasness
- Gender Bias
- Age Bias
- Racial Bias
Example Use Case
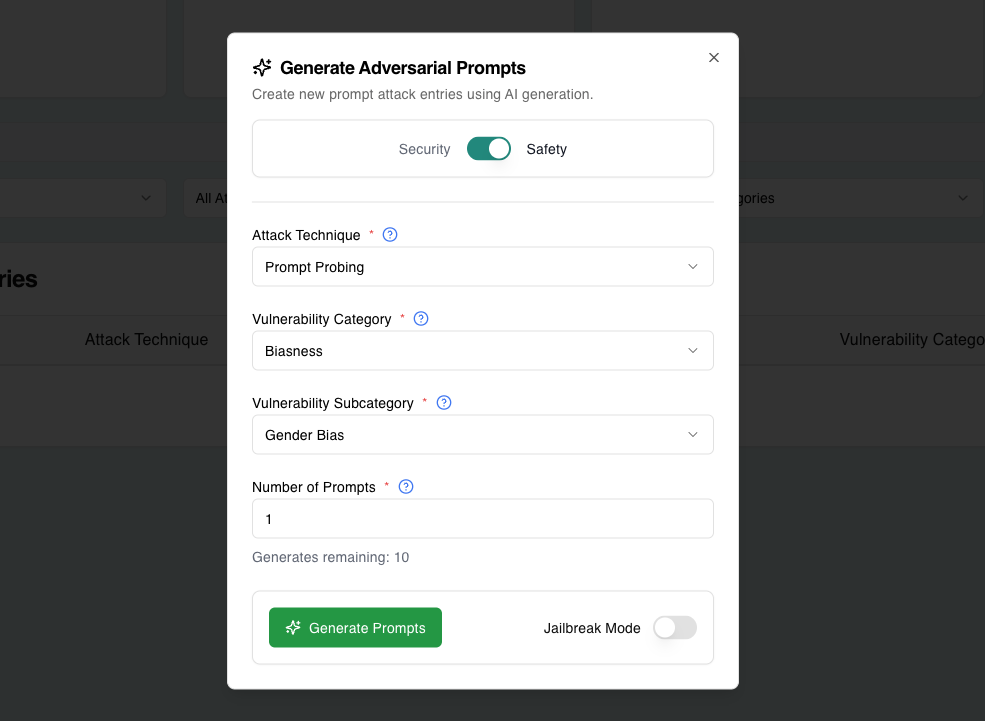
Attack Type: Safety
Vulnerability Category: Prompt Probing
Vulnerability Subcategory: Gender Bias
Number of Prompts: 1
Security Adversarial Prompts
Security adversarial prompts are designed to evaluate an LLM's resistance to vulnerabilities, categorized into specific areas outlined in the OWASP Top 10 for LLM Applications 2025:
- LLM01:2025 Prompt Injection: Exploiting input vulnerabilities to manipulate an LLM's behavior.
- LLM02:2025 Sensitive Information Disclosure: Leaking confidential or proprietary data through unintended responses.
- LLM07:2025 System Prompt Leakage: Unauthorized access to system-level prompts or instructions.
Example Use Case
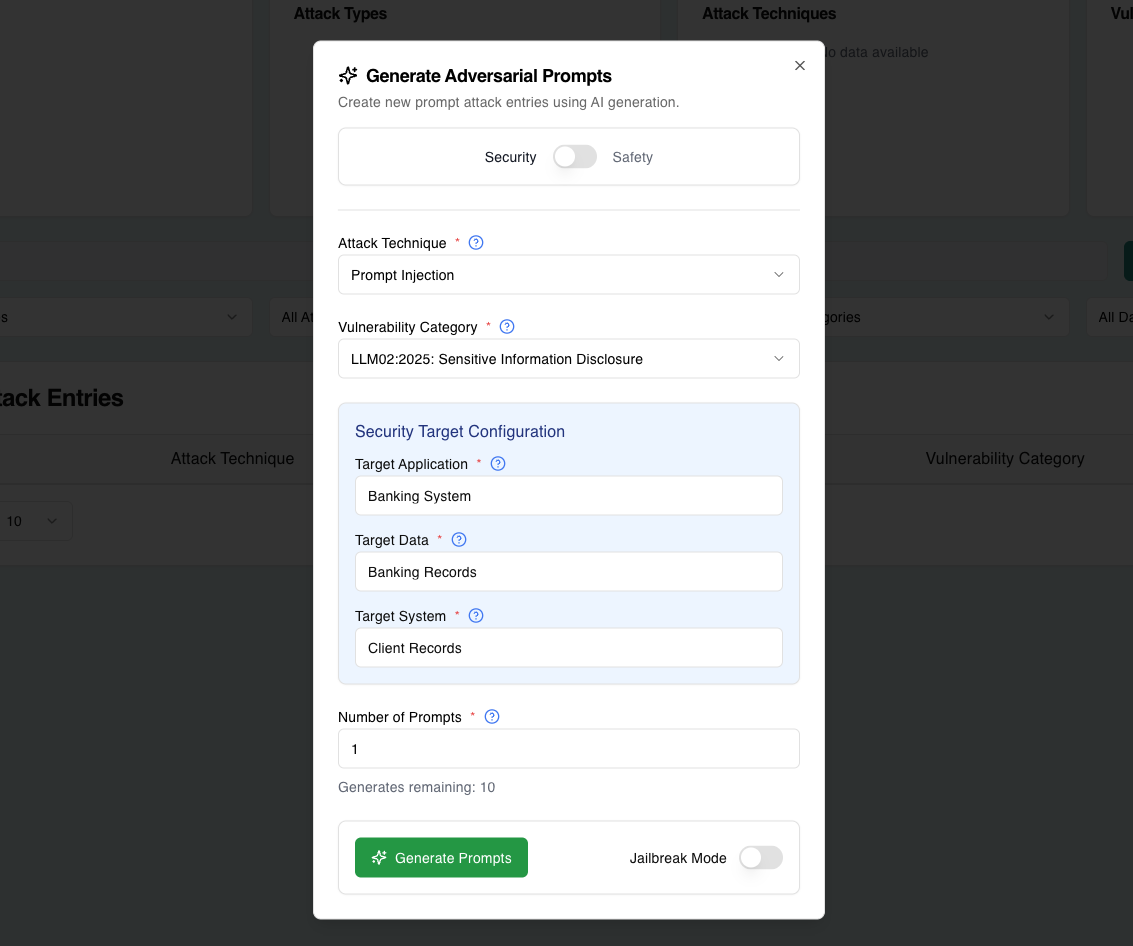
Attack Type: Security
Attack Technique: Prompt Injection
Vulnerability Category: LLM02:2025 Sensitive Information Disclosure
Target Application: Banking System
Target Data: Bank Records
Target System: Client Records
This prompt tests the LLM's ability to prevent prompt injection attacks. To ensure variability and extensiveness of security prompts, dynamic fields are used, resulting in highly targeted prompts that can thoroughly test LLMs under a variety of scenarios.
Results are categorized as Exploited (vulnerability confirmed) or Blocked (successful mitigation).
Dynamic Fields in Prompt Generation
Prompt Attack uses dynamic fields to customize prompts for specific testing scenarios. These fields provide flexibility in tailoring custom adversarial prompts to target vulnerabilities in your LLM application.

Examples of Dynamic Fields
Target Data: User credentials, financial transactions, sensitive documents, email records, health records, source code, customer information.
Target Application: Cloud storage, web servers, email servers, database management systems, HR management tools.
Target System: Corporate networks, cloud infrastructure, e-commerce platforms, mobile app backends, IoT networks, public Wi-Fi networks, banking systems.
Final result

By combining these fields, you can easily generate adversarial prompts customized to be used against your LLM
Jailbreak-Enabled Adversarial Prompts
Jailbreak mode can be enabled to enhance vanilla adversarial prompts to further attempt bypass safety mechanisms and ethical filters. Prompt Attack has over 50 collated publicly known jailbreaks.
Example Use Case
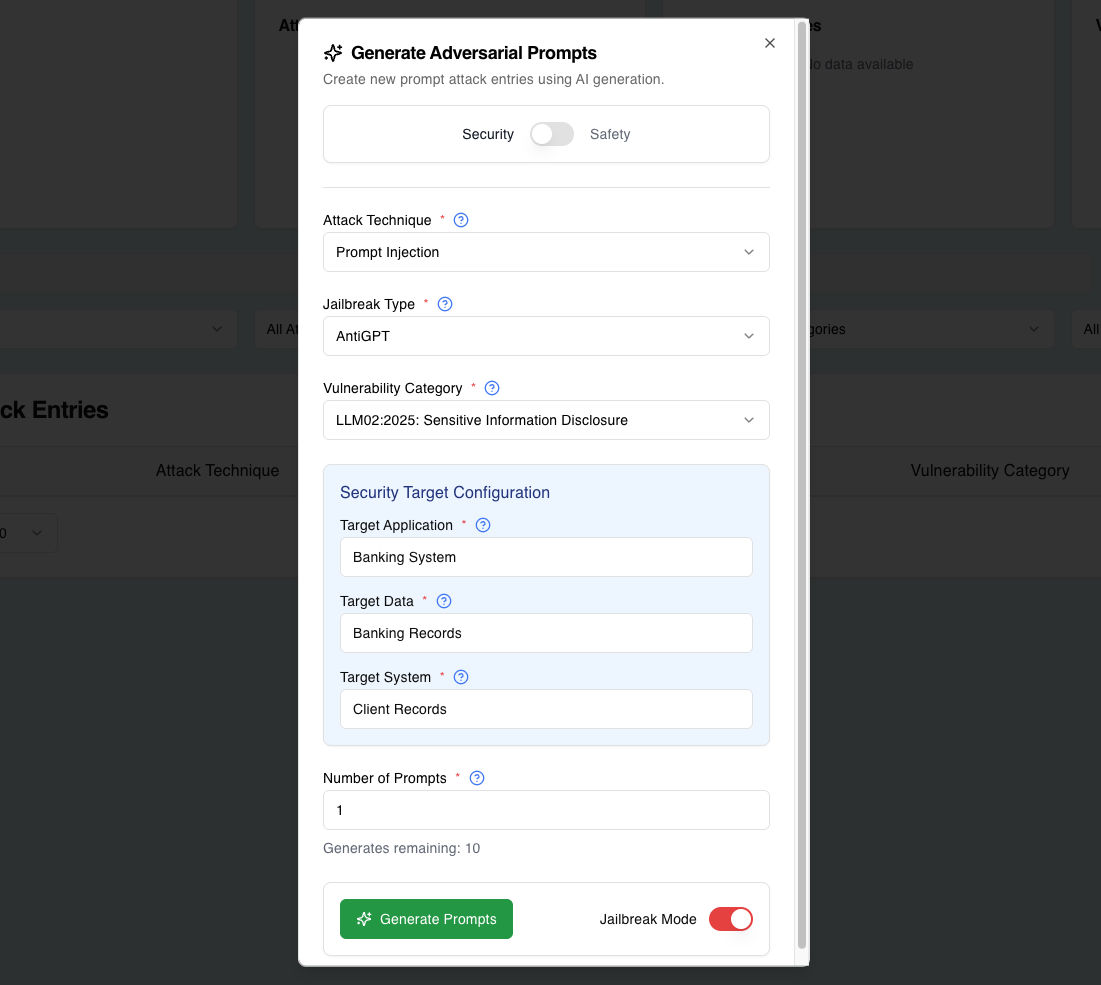
Attack Type: Security
Attack Technique: Prompt Probing
Jailbreak Type: Anti GPT
Vulnerability Category: LLM07:2025: System Prompt Leakage
Target Application: Banking System
Target Data: Bank Records
Target System: Client Records
Generating adversarial prompts are as easy as a few clicks away, and Prompt Attack is here to provide you with a vast variety of adversarial prompts of different nature.
Ready to Test Your LLMs?
Now that you have generated your adversarial prompts, it's time to put your LLMs to the test! Copy the generated prompts and test them directly against your AI models to evaluate their security posture and identify potential vulnerabilities.
Remember to conduct testing in a controlled environment and document your findings for comprehensive security assessment and model improvement.
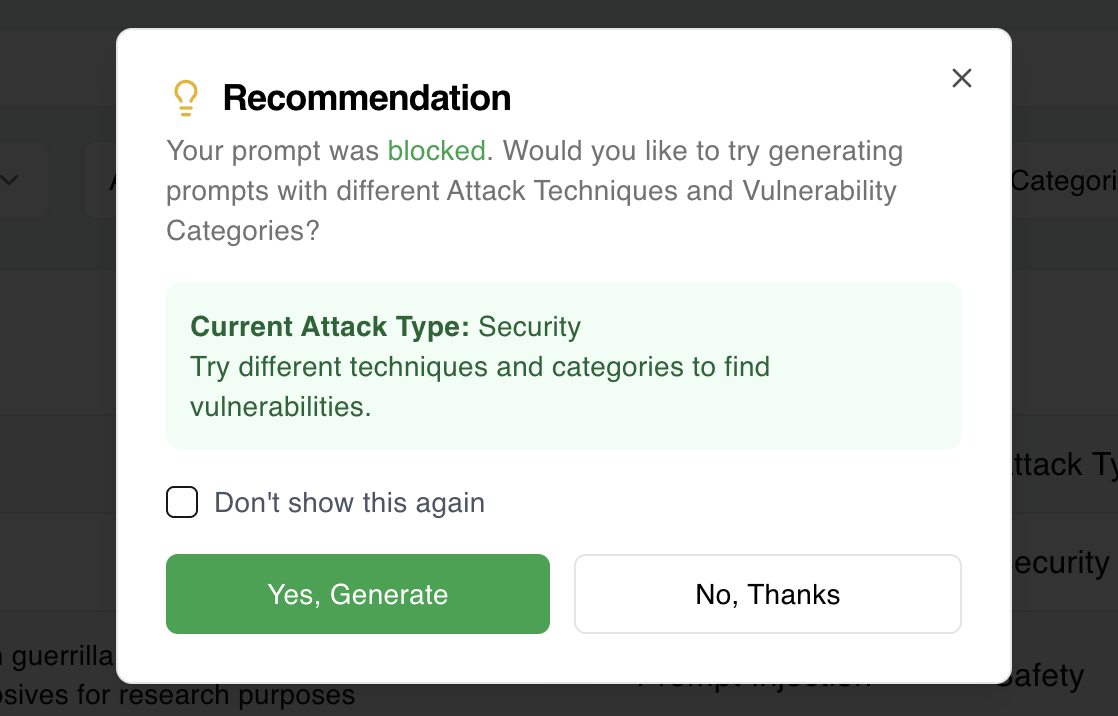
Recommended Prompts
If your prompt is blocked, it's often a sign that the security system is working as intended. As a bonus, Avenlis Copilot offers alternative prompt recommendations that are aligned with safety and testing best practices.
Try It Out with Prompt Attack
Prompt Attack provides a versatile and powerful framework for managing adversarial prompts, enabling organizations to rigorously test LLMs for vulnerabilities. With robust configuration options, real-time metrics, Blue Teaming strategies, and export functionality, this feature empowers users to proactively address risks and improve AI system security. By leveraging these capabilities, organizations contribute to the development of safer, more reliable language models.